The following article is an extended abstract submitted as part of AAAI’s New Faculty Highlights Program. Read the full-length article at this link: https://onlinelibrary.wiley.com/doi/10.1002/aaai.12070
Learning Causality with Graphs
Jing Ma, Jundong Li
University of Virginia, Charlottesville, VA, USA 22904
Abstract
Recent years have witnessed a surge in machine learning methods on graph data, especially those pow- ered by effective neural networks. Despite their success in different real-world scenarios, the majority of these methods on graphs only focus on predictive or descriptive tasks, while they lack any perspective of causality. Causal inference can reveal the causality inside data. An important problem in causal inference is causal effect estimation, which aims to estimate the causal effects of a certain treatment (e.g., prescrip- tion of medicine) on an outcome (e.g., cure of disease). In this paper, we introduce the background and challenges of causal effect estimation with graphs, and then summarize representative approaches in recent years. Furthermore, we provide some insights for future research directions.
Keywords: Causal effect estimation; Graph data; Causality; Observational data
1 Introduction of Causal Effect Estimation with Graphs
Graphs have been extensively used for modeling a plethora of real-world systems, including social media platforms, collaboration networks, biological networks, and critical infrastructure systems, to name a few. Cur- rently, the mainstream learning tasks on graphs are either predictive (e.g., node classification) or descriptive (e.g., measuring centrality) in nature. Most of studies on graphs address these tasks only from a statistical per- spective, e.g., utilizing the statistical correlations between node features and labels for node classification. But beyond the statistical level, we may also want to understand the causality of the learning process. Causal infer- ence is the process of determining causality. In causal inference, an important problem is to estimate the causal effects of a certain treatment (e.g., prescription of medicine) on an important outcome (e.g., cure of disease) for different individuals. The problem is known as causal effect estimation with a wide range of applications.
The gold standard of causal effect estimation is conducting randomized controlled trials (RCTs). How- ever, RCTs are often expensive, impractical or even unethical to conduct in many real-world scenarios [1]. Thus, many studies have been dedicated to causal effect estimation from observational data. However, most of these research works assume the observational data is independent and identically distributed (i.i.d.), while this traditional setting does not fit well in many scenarios, e.g., there may exist additional relational information such as social networks among individuals. With the rocketing availability of graph data across a myriad of influential areas, we are interested in developing novel frameworks to enable causality learning with graphs to facilitate many downstream applications [2, 3]. For example, given a social network of users, service providers need to decide whether the advertisement of a product (treatment) will help an individual user make a purchase (outcome) to provide better personalized recommendations.
In this paper, we analyze challenges of causal effect estimation with graphs, and summarize current repre- sentative works. Furthermore, we discuss several potential directions in this area.
2 Challenges of Causal Effect Estimation with Graphs
However, performing causal effect estimation with graphs remains a daunting task due to the following challenges: (1) Different modalities in graph data. The graph data contains different modalities including instance features as well as graph structure. How to jointly utilize these different modalities for causal effect estimation is the first challenge to address. (2) Existence of hidden confounders. Existing works are mostly based on the strong ignorability assumption [4, 5], which assumes that no hidden confounders exist. Here, confounders are variables (e.g., user’s preferences) that causally affect both treatment assignment (e.g., advertising the user receives) and outcome (e.g., user’s purchase pattern). Hidden confounders are confounders which can not be di- rectly observed. However, such assumption is difficult to be satisfied in real-world observational data. Existing
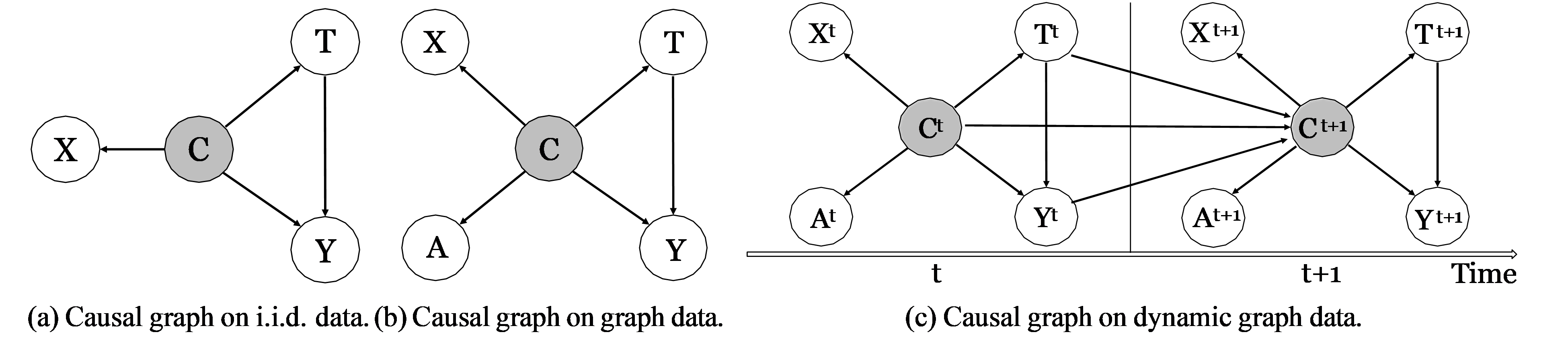
Figure 1: Causal graphs commonly used under different assumptions of observational data, including i.i.d. data [6], graph data [7], and dynamic graph data [8]. Each circle denotes a variable, and each arrow stands for a causal relation. The grey circles are unobserved variables, while other white ones are observed. X, C, T, Y, A here denotes instance features, confounders, treatment assignment, outcome, and graph structure, respectively. The superscript (·)t denotes a variable at time stamp t.
methods based on such assumption may result in biased estimation of causal effect. An initial exploratory [6] attempts to utilize instance features to infer the hidden confounders based on the causal graph shown in Fig. 1 (a), but this work is still limited in i.i.d. data. (3) Complicated forms of graphs. Many real-world graphs are complicated, e.g., dynamic graphs. Typical examples include interactions among individuals in an epi- demic during different time periods. Performing causal effect estimation on these graphs is often difficult as it requires us to control for the hidden confounders in a complicated evolving environment.
3 Methods of Causal Effect Estimation with Graphs
Despite the aforementioned challenges, opportunities are also unequivocally present with the graph data – although the hidden confounders are notoriously hard to measure, we can capture them by incorporating the underlying graph structure. For example, the purchasing preferences (hidden confounders) are often encoded implicitly in the social network. We introduce several works which bridge the knowledge gap by developing novel causal inference frameworks for causal effect estimation with graphs.
Network deconfounder. To mitigate the confounding biases for individual-level treatment effect (ITE) es- timation, Guo et al. [7] use a weaker version of strong ignorability assumption, and assume that the hidden confounders can be captured from the proxy variables for them, i.e., the variables which have dependencies with the hidden confounders. As the causal graph shown in Fig. 1 (b), both instance features X and graph structure A can serve as proxy variables to infer the hidden confounders C. Guo et al. [7] propose a graph convolutional networks (GCNs) based method — network deconfounder [7], which utilizes the graph structure as well as the instance features to learn the representation of hidden confounders for ITE estimation on graphs. Minimax game between representation balancing and treatment prediction. To further enhance the per- formance of ITE estimation on graph data, Guo et al. [9] consider two desiderata for ITE estimation: 1) On the group level, existing works [5, 10] have proved that minimizing the discrepancy between the representation distributions of treatment group and control group can help mitigate the biases in ITE estimation. 2) On the individual level, the learned confounder representations are desired to capture patterns of hidden confounders which can predict treatment assignments. As these two desiderata often contradict each other, this work pro- poses a minimax game based network ITE estimator (IGNITE) [9] to achieve these two desiderata.
Deconfounding in dynamic networks. Most existing works overwhelmingly assume that the observational data and the relations among them are static. However, these data and their relations are naturally dynamic in many real-world scenarios. Considering this, Ma et al. [8] propose a framework Dynamic Network DeCon- founder (DNDC) for ITE estimation in time-evolving networked observational data. This framework is based on the causal graph shown in Fig. 1 (c), where the hidden confounders at current time stamp can be influenced by historical confounders, treatment assignments, and outcomes. Generally, DNDC learns representations of hidden confounders over time by mapping the current networked observational data and historical information into the same representation space. More specifically, recurrent neural networks (RNNs) [11] are utilized to capture the historical information, and GCNs [12] are used to encode the network structure in each time stamp.
4 Discussion and Future Work
Despite the contributions of existing works, there still remain lots of potential challenges and tasks to address in the future: 1) Causal effect estimation under complicated networked data: Currently, most existing works of causality learning with graphs assume these graphs are simple and homogeneous graphs, while in many real- world scenarios, more complicated relational information can also be considered, e.g., heterogeneous graphs, hypergraphs [13], and knowledge graphs. 2) Network interference in complicated scenarios: Although many efforts have been made to address the problem of causal effect estimation under the existence of interference, most of them are still based on some strong assumptions with respect to the network structure (e.g., simple graphs) and the existence of hidden confounders (e.g., strong ignorability). Future works which can relax these assumptions would be highly impactful. 3) Interpretation in causality learning: Aside from the performance of causal effect estimation, most of existing works which control for confounders, especially those based on neural network, lack any interpretation of the causal effect estimation process. Some works [14–16] identify disentangled representations to distinguish the underlying factors regarding the treatment, outcome, or confounders. These works promote the interpretation of the learned representations in a causal perspective, but are still based on i.i.d. data. 4) Causal domain adaptation/generalization on graphs: Recent studies have revealed the importance of incorporating causal perspective to remove the spurious correlations [17] and enhance the performance of domain adaptation/generalization. Nevertheless, it becomes a more challenging task on graphs as the biases brought from spurious correlations might be amplified through the graph structure.
Acknowledgements
This work is supported by the National Science Foundation under grant IIS-2006844, IIS-2144209, and CNS- 2154962, the JP Morgan Chase Faculty Research Award, and the 3 Cavaliers seed grant. The authors have no conflicts of interest to report.
References
[1] C. E. Goldstein, C. Weijer, J. C. Brehaut, D. A. Fergusson, J. M. Grimshaw, A. R. Horn, and M. Taljaard, “Ethical issues in pragmatic randomized controlled trials: a review of the recent literature identifies gaps in ethical argumentation,” BMC Medical Ethics, 2018.
[2] J. Ma, Y. Dong, Z. Huang, D. Mietchen, and J. Li, “Assessing the causal impact of covid-19 related policies on outbreak dynamics: A case study in the us,” arXiv preprint arXiv:2106.01315, 2021.
[3] J. Ma, R. Guo, M. Wan, L. Yang, A. Zhang, and J. Li, “Learning fair node representations with graph counterfactual fairness,” in Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022.
[4] J. L. Hill, “Bayesian nonparametric modeling for causal inference,” Journal of Computational and Graph- ical Statistics, 2011.
[5] U. Shalit, F. D. Johansson, and D. Sontag, “Estimating individual treatment effect: generalization bounds and algorithms,” in International Conference on Machine Learning, 2017.
[6] C. Louizos, U. Shalit, J. M. Mooij, D. Sontag, R. Zemel, and M. Welling, “Causal effect inference with deep latent-variable models,” in Advances in Neural Information Processing Systems, 2017.
[7] R. Guo, J. Li, and H. Liu, “Learning individual causal effects from networked observational data,” in
International Conference on Web Search and Data Mining, 2020.
[8] J. Ma, R. Guo, C. Chen, A. Zhang, and J. Li, “Deconfounding with networked observational data in a dynamic environment,” in ACM International Conference on Web Search and Data Mining, 2021.
[9] R. Guo, J. Li, Y. Li, K. S. Candan, A. Raglin, and H. Liu, “Ignite: A minimax game toward learning individual treatment effects from networked observational data,” in International Joint Conference on Artificial Intelligence, 2020.
[10] L. Yao, S. Li, Y. Li, M. Huai, J. Gao, and A. Zhang, “Representation learning for treatment effect estima- tion from observational data,” Advances in Neural Information Processing Systems, 2018.
[11] L. R. Medsker and L. Jain, “Recurrent neural networks,” Design and Applications, 2001.
[12] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in Inter- national Conference on Learning Representations, 2017.
[13] J. Ma, M. Wan, L. Yang, J. Li, B. Hecht, and J. Teevan, “Learning causal effects on hypergraphs,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2022.
[14] N. Hassanpour and R. Greiner, “Learning disentangled representations for counterfactual regression,” in
International Conference on Learning Representations, 2019.
[15] W. Zhang, L. Liu, and J. Li, “Treatment effect estimation with disentangled latent factors,” arXiv preprint arXiv:2001.10652, 2020.
[16] J. Ma, R. Guo, A. Zhang, and J. Li, “Multi-cause effect estimation with disentangled confounder repre- sentation,” in International Joint Conference on Artificial Intelligence, 2021.
[17] M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant risk minimization,” arXiv preprint arXiv:1907.02893, 2019.
Author Biographies
Jing Ma is a Ph.D. candidate in the Department of Computer Science at University of Virginia. Her research interests include causal inference, machine learning, data mining, and graph mining. Especially, her research targets on bridging the gap between causality and machine learning. Her works have been published in many top conferences and journals such as KDD, IJCAI, WWW, AAAI, TKDE, WSDM, SIGIR, and IPSN. Jundong Li is an Assistant Professor in the Department of Electrical and Computer Engineering, with a joint appointment in the Department of Computer Science, and the School of Data Science at University of Virginia. He received Ph.D. degree in Computer Science at Arizona State University in 2019. His research interests are in data mining, machine learning, and causal inference. He has published over 100 articles in high-impact venues (e.g., KDD, WWW, AAAI, IJCAI, WSDM, EMNLP, CSUR, TPAMI, TKDE, TKDD, and TIST.). He has won
several prestigious awards, including NSF CAREER Award, JP Morgan Chase Faculty Research Award, Cisco Faculty Research Award, and being selected for the AAAI 2021 New Faculty Highlights program.